SafeProgram#
查看导出函数表可以发现 TlsCallback,从这里入手分析。

第一个 tls_callback 注册 VEH,之后在注册表写入CRC的 checksum 值。第二个对代码段进行扫描并且查表计算CRC,和注册表保存的 checksum 比对,不一致则退出程序。
主函数一上来开了新的线程,而且每隔1000ms递归创建新线程。因为tls回调函数在线程创建或者终止时都会调用,所以这里是在循环检测CRC。绕过检测的方法比较多,直接的方法是patch 删去 TLS_CALLBACK1 中调用的CRC检测函数。也可以在调试时只使用硬件断点。
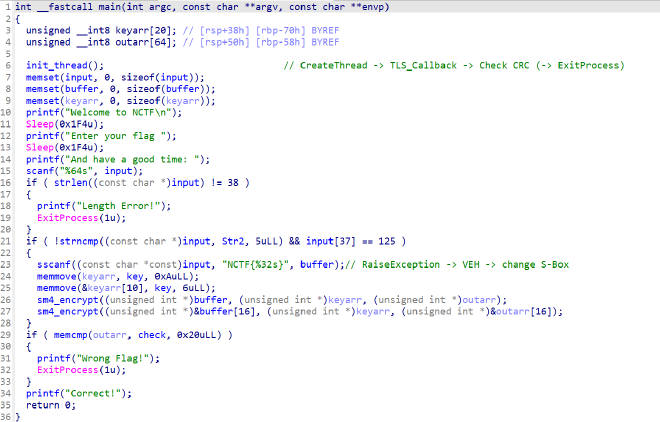
后面就是常规的输入-加密-检查过程。加密函数是SM4,可以根据S盒的特征推测,或者绕过 CRC 之后调试分析得出。要注意的是加密之前,程序主动触发除零异常,调用 VEH 异常处理函数修改了 key 和 Sbox
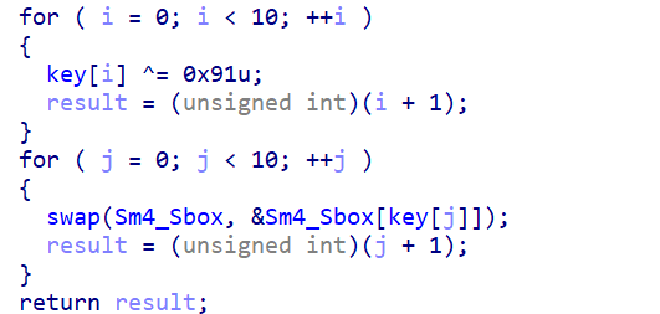
解密的话可以dump下来修改后的S盒以及key,然后找一个SM4的脚本,修改Sbox之后解密即可。
ezDOS#
MASM 写的16位程序。拿IDA打开,静态分析的话有多处花指令干扰。
一共有两种类型的花指令,都是比较常规的。
第一类:永恒跳转,nop掉即可。
jnz offset lable
jz offset lable + 1
第二类基于堆栈的 call +ret。al 经过一系列计算得到一个固定的值,加到 dl 然后 push 到栈上,间接修改了堆栈末尾的返回地址,retf 回去就会改变正常的控制流,跳过部分指令。
call far ptr junkskip
junk segment
junkskip:
pop dx
push ax
xor ax, ax
; ...
add dl, al
pop ax
push dx
retf
junk ends
这种可能比较隐蔽,因为直接 call 进一个单独的函数,容易把它当成加密的一部分。这里没有加 0xE8 之类的 junkcode 干扰反汇编,而是使用正常的指令,一定程度上也起到混淆加密流程的作用。
找一个DOS环境,比如DOSBox之类的模拟器调试一下,基本就没什么困难了。动调时也能跟踪到 retf 之后控制流返回的地址。最终能分析出加密算法是部分魔改的RC4,改动的地方如下:
- S盒逆序初始化
- key 左移3位,右移5位
- 密钥流生成的值 加1
到这里就可以写脚本解密。考虑到RC4的流密码性质,这道题也可以采用更简单的做法:动调记录密钥流,之后和密文逐一异或得到flag。
data = [0x7C, 0x3E, 0x0D, 0x3C, 0x88, 0x54, 0x83, 0x0E, 0x3B, 0xB8,
0x99, 0x1B, 0x9B, 0xE5, 0x23, 0x43, 0xC5, 0x80, 0x45, 0x5B,
0x9A, 0x29, 0x24, 0x38, 0xA9, 0x5C, 0xCB, 0x7A, 0xE5, 0x93,
0x73, 0x0E, 0x70, 0x6D, 0x7C, 0x31, 0x2B, 0x8C]
key = b"NCTf2024nctF"
modikey = [((char<<3)|(char>>5))&0xFF for char in key]
S = [255 - m for m in range(256)]
T = [modikey[n % len(modikey)] for n in range(256)]
j = 0
for i in range(256):
j = (j + S[i] + T[i]) % 256
S[i],S[j] = S[j],S[i]
i = j = t = 0
for k in range(len(data)):
i = (i + 1) % 256
j = (j + S[i]) % 256
t = (S[i] + S[j]) % 256
S[i],S[j] = S[j],S[i]
data[k] ^= (S[t] + 1)
print(bytes(data).decode())
x1Login#
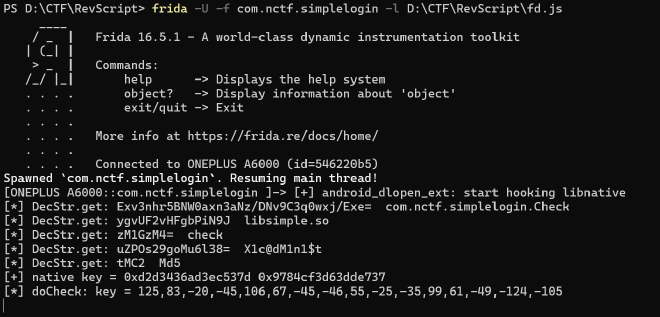
这题用frida可以很快做出来,但是首先看一下常规方法
静态分析发现 Java层有root检测和反调试。常规绕过方法应该是apktool解包修改smali代码,再重新打包签名。同时java层有字符串混淆,分析 libsimple.so 得出算法是先异或字符串长度之后换表base64,之后可以写脚本去混淆。
继续分析 MainActivity 能够发现动态加载dex,这个过程也会调用一个native方法 loadDEX。分析另外一个动态库 libnative.so,加载的流程为:从assets提取名为 libsimple.so 的文件,之后从0x40偏移开始把内容复制到byte数组中,返回到 java层的 InMemoryDexClassLoader。
这里的 libsimple.so是假的ELF,只有前0x40字节是elf_header,后面则是真正的dex。修复后反编译如下:
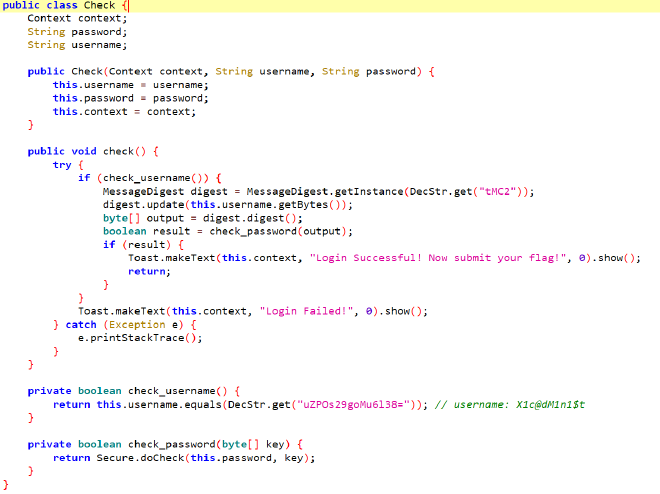
username可以去混淆得到,用户名验证通过后把自身的md5作为密钥,传给 Secure.doCheck 进一步验证password。这又是一个native方法,不过已经到最后的加密部分了。看流程,先加密后解密再加密,大概能猜到是3DES,如果用findcrypt也能够查出来DES特征。
标准3DES就不多说了,不放心可以调试,加密函数内部也特意留了 __android_log_print 方便查看结果。最后特别要注意的是字节序的问题,因为DES是64-bit的分组加密,所以明文、密文还有密钥都直接用的 uint64_t 类型,整个过程都遵循小端序。
在cyberchef解一下得到password。
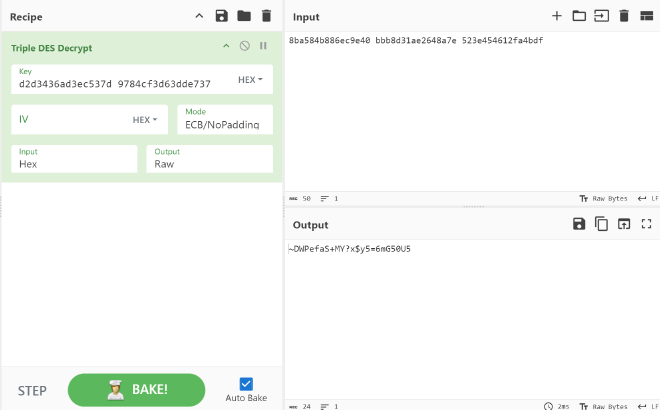
username: X1c@dM1n1$t
password: SafePWD~5y$x?YM+5U05Gm6=
接下来给出基于frida hook的快捷做法。
- 过root检测和反调试:hook
checkDebug和checkRoot,修改返回值为false - 字符串去混淆:hook
DecStr.get的参数和结果 - dex加载:hook
InMemoryDexClassLoader的构造函数或者Secure.loadDex,拿到bytearray形式的dex字节码。 用开源工具frida-dexdump可能容易一点,但是要手动挨个看哪个dex是要找的,一般逆向题的dex不会很大,找那种几kb的就行。 - 算法分析:可以hook native,找到 key 和 加密过程的中间变量。
完整js脚本如下
function Start_Hook(){
Start_NativeHook("libnative");
Java.perform(function(){
var Sec = Java.use("com.nctf.simplelogin.Secure");
Sec.checkRoot.implementation = function (){
return false;
};
Sec.checkDebug.implementation = function (){
return false;
};
var DecStr = Java.use("com.nctf.simplelogin.DecStr");
//overload('java.lang.String')
DecStr.get.implementation = function (str) {
var result = this.get(str);
console.log(`[*] DecStr.get: ${str} ${result}`);
return result;
};
//overload('java.lang.String', '[B')
Sec.doCheck.implementation = function (str,barr) {
var result = this.doCheck(str,barr);
console.log(`[*] doCheck: key = ${barr}`);
return result;
};
});
}
function Start_NativeHook(libname) {
var dlopen = Module.findExportByName(null, "android_dlopen_ext");
Interceptor.attach(dlopen, {
onEnter: function (args) {
var filePath = args[0].readCString();
if (filePath.indexOf(libname) != -1) {
console.log(`[+] android_dlopen_ext: start hooking ${libname}`)
this.isCanHook = true;
}
}, onLeave: function (retValue) {
if (this.isCanHook) {
this.isCanHook = false;
hook_native();
}
}
})
}
function hook_native(){
var target_addr = Module.findBaseAddress("libnative.so").add(0x1F1C);
Interceptor.attach(target_addr,{
onEnter: function (args) {
var key0 = this.context.x22;
var key1 = this.context.x23;
console.log(`[+] native key = ${key0} ${key1}`);
},
onLeave: function (retval) {}
});
}
setImmediate(Start_Hook);
gogo#
首先恢复符号。目前高版本IDA已经能自动恢复golang符号,如果用 go_parser 插件也能恢复的差不多。
主要逻辑是用协程实现了两个并发的寄存器虚拟机,分别加密flag的前后两部分。解题思路依然是还原vm字节码,只要能还原到汇编级别就足以正常分析。
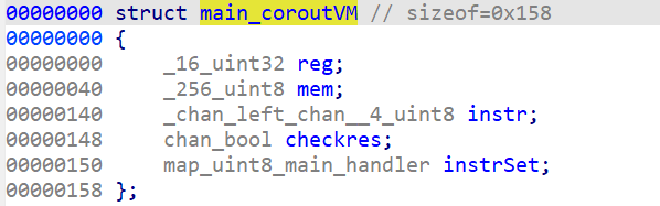
在IDA可以找到vm的结构体。前两个好理解,对应寄存器和cache缓存,后面两个是缓冲channel,分别向vm传入字节码和等待返回运行结果,最后一个map是指令集。从 instr 管道的4字节长度和 handler的参数可以推测出vm使用4字节的定长指令集,看指令名称也可以发现类似ARM。
两个虚拟机的指令集不同,对应的初始化在 main_init 里面,依次定义了两个map类型变量。指令函数 handler 是二者共用的,需要逆向分析 opcode 和 handler 的对应关系,这里直接给出结论:
type handler func(vm *coroutVM, operands [3]byte)
var instructionSetA = map[byte]handler{
0x11: LDR,
0x12: LDRI,
0x15: STR,
0x16: STRI,
0x2A: MOV,
0x41: ADD,
0x42: SUB,
0x47: MUL,
0x71: LSL,
0x73: LSR,
0x7A: XOR,
0x7B: AND,
0xFE: RET,
0xFF: HLT,
}
var instructionSetB = map[byte]handler{
0x13: LDR,
0x14: LDRI,
0x17: STR,
0x18: STRI,
0x2B: MOV,
0x91: ADD,
0x92: SUB,
0x97: MUL,
0xC1: LSL,
0xC3: LSR,
0xCA: XOR,
0xCB: AND,
0xFE: RET,
0xFF: HLT,
}
分析 main_main,发现程序将flag拆分成20字节的明文块,分别复制到虚拟机的缓存中。接着同时开启两个vm的协程,并向 instr 管道发送相同的字节码指令,两个虚拟机的指令混在一起,只有能匹配上vm自身指令集的指令会被执行。还原指令时,根据opcode把二者的指令分开会更方便分析。
大多数指令的结构都是 opcode(1byte) + dst reg(1byte) + src reg(2byte),也有例如 MOV 这样涉及立即数的指令,最好结合调试对应的 handler 函数来进一步确定各 operand 的含义。分析清楚指令结构之后,就可以dump出程序中的vm字节码,写一个自动化或者半自动化的脚本进行还原。这里给出一个可用的 golang 脚本
package main
import (
"fmt"
"os"
)
var InstructionSetA = map[byte]string{
0x11: "LDR",
0x12: "LDRI",
0x15: "STR",
0x16: "STRI",
0x2A: "MOV",
0x41: "ADD",
0x42: "SUB",
0x47: "MUL",
0x71: "LSL",
0x73: "LSR",
0x7A: "XOR",
0x7B: "AND",
0xFE: "RET",
0xFF: "HLT",
}
var InstructionSetB = map[byte]string{
0x13: "LDR",
0x14: "LDRI",
0x17: "STR",
0x18: "STRI",
0x2B: "MOV",
0x91: "ADD",
0x92: "SUB",
0x97: "MUL",
0xC1: "LSL",
0xC3: "LSR",
0xCA: "XOR",
0xCB: "AND",
0xFE: "RET",
0xFF: "HLT",
}
func dis(instrSet map[byte]string, bytecode [4]byte) {
opcode := bytecode[0]
operands := bytecode[1:]
if instr, exists := instrSet[opcode]; exists {
switch instr {
case "LDR":
fallthrough
case "STR":
fmt.Printf("%s R%d, R%d", instr, operands[0], operands[1])
case "LDRI":
fallthrough
case "STRI":
fmt.Printf("%s R%d, #%x", instr, operands[0], operands[2])
case "MOV":
imm := int32(operands[1]) + int32(operands[2])<<8
fmt.Printf("%s R%d, #%x", instr, operands[0], imm)
case "RET":
fmt.Printf("%s R%d", instr, operands[0])
case "HLT":
fmt.Printf("%s", instr)
default:
fmt.Printf("%s R%d, R%d, R%d", instr, operands[0], operands[1], operands[2])
}
fmt.Print("\n")
}
}
func disasm(instrSet map[byte]string) {
var instrcode [4]byte
data, _ := os.ReadFile("bytecode_dump.bin")
for i := 0; i < len(data); i += 4 {
copy(instrcode[:], data[i:i+4])
dis(instrSet, instrcode)
}
}
func main(){
disasm(InstructionSetA)
disasm(InstructionSetB)
}
如果能顺利还原字节码,那么这道题的难点就解决了。接下来就是根据可读性更好的汇编来分析加密算法。以第二个虚拟机执行的字节码为例。

其实特征已经相当明显,看到 9e3779b9 就已经确定TEA系列,继续向下看移位部分,是xxtea的特征。唯一魔改的地方在于原来标准算法中的左移换成右移,右移换成左移。第一个虚拟机中算法没有改动,是标准xxtea。
字节码虽然看起来很多,但基本上是若干轮循环的重复。两个vm密钥不同,不过都是在前几轮加密中通过 MOV 指令写入缓存,所以只需要逆前几轮循环,找齐密钥就可以去解密。
keyA := int32[4]{0x6e637466, 0x062ef0ed, 0xa78c0b4f, 0x32303234}
keyB := int32[4]{0x32303234, 0xd6eb12c3, 0x9f1cf72e, 0x4e435446}